Tree of Thoughts: Deliberate Problem Solving with Large Language Models
文章信息
2023nips,DeepMind
背景目的及结论
背景
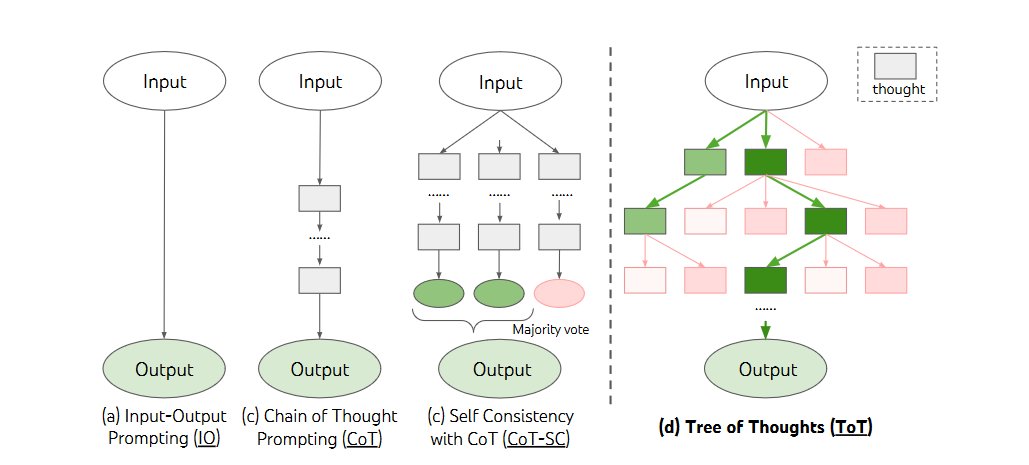
Input-output (IO) prompting:普通的IO输入输出
Chain-of-thought (CoT) prompting:思维链的输入输出
Self-consistency with CoT (CoT-SC):自一致性的思维链
但是这些模型没有对于思维过程进行局部探索,并且最频繁的启发式搜索仅在输出空间有限时适用
当前的模型仍然是以从左到右的方式逐一做出token级的决定,这样一个简单的机制是否足以让LM朝着一般问题解决者的方向发展?
研究表明,人有两种参与决策的模式–快速、自动、无意识的模式(”系统1”)和缓慢、慎重、有意识的模式(”系统2”)。
我们想探索系统2:维护和探索当前选择的不同备选方案,而不仅仅是挑选一个;评估当前状态并积极展望未来或回溯以做出更多全局决策。
目的
生成一种第二种决策模式的方案,把从左到右生成答案的过程给他变成一个在树空间进行搜索的过程
Such a high-level semantic unit allows the LM to self-evaluate the progress different intermediate thoughts make towards solving the problem through a deliberate reasoning process that is also instantiated in language (Figures 2,4,6).
结论
给出了三个自己做的任务,24点,创意写作,填词游戏,分别在这三个游戏中的很好的结果,本质上是通过构建树的过程去达到让模型去思考的结果
这些模型在解决问题时仍然局限于从左至右的决策过程,这意味着它们可能在需要探索、战略预见或需要初步决策扮演重要角色的任务中表现不佳。为了克服这些挑战,论文提出了一个新的语言模型推理框架,名为Tree of Thoughts (ToT)。
- 语言模型推理时局限于token级别、从左到右的决策过程。
- 本文提出了一个新的语言模型推理框架ToT(Tree of Thoughts,思维树)。
- 概括了流行的CoT(Chain of Thought,思维链)方法来提示模型,可以探索连贯的文本单元(想法)作为解决问题的中间步骤。
- ToT允许模型通过考虑多种不同的推理路径和自我评估选择来执行深思熟虑的决策,并在必要时向前看或回溯以做出全局选择。
we propose three new problems that challenge existing LM inference methods even with the state-of-the-art language model, GPT-4 [20]: Game of 24, Creative Writing, and Crosswords (Table 1). These tasks require deductive, mathematical, commonsense, lexical reasoning abilities, and a way to incorporate systematic planning or search. We show ToT obtains superior results on all three tasks by being general and flexible enough to support different levels of thoughts, different ways to generate and evaluate thoughts, and different search algorithms that adapt to the nature of different problems. We also analyze how such choices affect model performances via systematic ablations and discuss future directions to better train and use LMs.
As Figure 1 illustrates, while existing methods (detailed below) sample continuous language sequences for problem solving, ToT actively maintains a tree of thoughts, where each thought is a coherent language sequence that serves as an intermediate step toward problem solving (Table 1). Such a high-level semantic unit allows the LM to self-evaluate the progress different intermediate thoughts make towards solving the problem through a deliberate reasoning process that is also instantiated in language (Figures 2,4,6).
结果与讨论
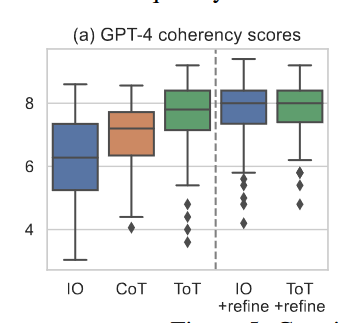
结果主要是在作者提出的三个游戏中得到了优于以上提出的三种背景中的提问形式
TOT的具体实施过程:
问题分解
如何将想要的问题分解为合适的中间步骤的子问题是有讲究的,问题不能太大也不能太小,
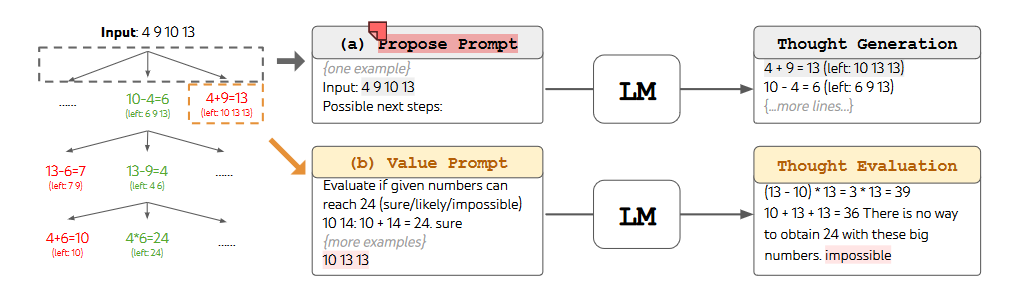
思想生成
有两种方式可以生成候选的答案
- 采样
- 直接使用大模型进行采样,这种方法更适用于思考空间丰富的情况,例如每个思考点都是一个段落。
- 提示建议
- 使用大模型在建议中进行采样,这种方法在思考空间更受限的情况下效果更好,例如每个思考点只是一个单词或一行。
状态评估
- 打分
- 可以给每个状态打分(1-10)
- 投票
- 让模型进行投票对多个答案进行投票
搜索算法
仅使用BFS或DFS
24点游戏
对于Baselines(I/O,CoT)来说,可以使用refine的方法,对于答案进行精炼
对于ToT来说,使用BFS就可以进行搜索了,每次value就行
创造性写作
ToT:进行BFS,使用5层的宽度,树的第一层可以生成一个写作的计划,对这五个进行投票之后,再去生成五篇文章
填词游戏
DFS:可以将这个游戏分成字母,单词,和整局游戏的输赢,把DFS中最深的输出给输出出来
文章优势
- 开头的那个系统一系统二的论述真的是一个好的讲故事的方法
- 传统的数据结构运用在这个思维构建的过程中,像有个很著名的算法好像就是放在队列里面
- 任务的选取也很好,问题选的不大不小
- 设计baseline中对于CoT和IO的设计,包括refine和回溯
自我想法
思考
是不是在考虑基础数据结构在模型中的应用,并且其他算法的思想是不是也是可以运用进来的。并且不止是算法的思想,还可以使用一些其他方面的思想,思路不要被固定住
图表
句式
Here we explore 5 × 5 mini crosswords as a harder search problem involving natural language. Again, the goal is not just to solve the task, as more general crosswords can be readily solved with specialized NLP pipelines [31] that leverages large-scale retrieval instead of LM. Rather, we aim to explore the limit of LM as a general problem solver that explores its own thoughts and guides its own exploration with deliberate reasoning as heuristics.
The literature on human cognition provides some clues to answer these questions. Research on “dual process” models suggests that people have two modes in which they engage with decisions – a fast, automatic, unconscious mode (“System 1”) and a slow, deliberate, conscious mode (“System 2”)
Graph of Thoughts: Solving Elaborate Problems with Large Language Models
文章信息
AAAI2024
背景
背景
生成prompt的方法越来越多,如最近的CoT,cotsc、tot等,但是这些方法都限制了模型在思维过程中的推理能力,对于ToT来说他将整个思维过程限制到了整个树状结构中。而根据我们人脑的一些神经活动,人的推理过程,算法的执行过程来看,更加好的推理过程可以被生成通过使用任意的图结构(arbitrary graph structure),例如,人们可以将以前思维链的想法和现在的想法相结合,而不是直接抛弃他,并且使用他们的优点,消除他们的缺点,以此来形成一个更好的答案。优化一个更加好的推理过程
目的
生成一个任意的图状结构,来完成更加复杂的思维过程。并且提出了五个贡献
结论
在生成的三个问题中得到了SOTA,好像这种方式真的有帮助模型在思维框架下进行思考
AUTOMATIC CHAIN OF THOUGHT PROMPTING IN LARGE LANGUAGE MODELS
文章信息
2023ICLR;CoT;
研究背景(问题)
对于CoTSc和CoT来说,对于CoT的构建都是手工的,需要自己针对每一个任务去给出针对性的fewshot的范例,虽然这样的效果很好,但是相对来说是很麻烦的,对于每个任务都要去手动的给出相应的示例,需要自己去挑选示例,并且对于我们的挑选的范例的要求也是一个挑战。
相对于ZeroShot来说,虽然这句话对于每个任务都适用,但是对于每个任务来说效果肯定不如FewShotCoT,可以使用
方法
结论
思考(展望)
学习
Large Language Models are Zero-Shot Reasoners
文章信息
nips2022;CoT;
研究背景(问题)可以一段一段写
主要的研究问题是在LLM背景之下,如何研究prompt成了NLP领域的热门话题。在直观的单步系统system1中LLM表现还不错,但是在一些需要推理的问题System2中,表现的不是很尽如人意。但是在FewShot CoT出现之后这个问题可以说得到了显著的改善。但是FewshotCoT中还只是相对于特定任务,对于一些需要推理的相对于广泛的下游任务还是无法尽到作用。第二,还有缩放scaling laws的任务,第三给以后的任务提供一个基线。
方法
实验过程相当简单,这边给了两个步骤,第一步是把问题和生成思维链的提示句进行了拼接,第二步是把第一步的整个提问和答案拼接,再加一个抽取答案的提示就形成了答案抽取的提示。
结论
实验
实验给出了ZeroShotCoT在12个数据集上的实验结果。试验所使用的模型分别是GPT系列和PaLM系列。实验还添加了
结果
结果是ZSCoT实验结果远远大于ZS。个人理解:因为推理的作用,生成答案的结果使得大模型思考的时间变长了,所以生成的结果更加的准确了。==并且对于一些不太正确的结果来说,其实有些推理过程也是正确的。==说明这个推理的过程确实是有用的。
对于CoT来说,对于大模型的效果要远大于小模型,==难道这就是所说的缩放定律吗==
并且下面还有一段话,”如果给出的提示和所要解答的问题格式不对应的话,那么效果会很差,意思是大模型是按图索骥,仅仅是按照给定的问题的过程去进行套用吗”
In contrast, the performance gain becomes much less when using examples with different answer types (to MultiArith), confirming prior work [Min et al., 2022] that suggests LLMs mostly leverage the few-shot examples to infer the repeated format rather than the task itself in-context. Nevertheless, for both cases the results are worse than Zero-shot-CoT, affirming the importance of task-specific sample engineering in Few-shot-CoT.
思考(展望)
- 作者说错误的fewshot格式会影响最终结果的正确性,我在如果给出的示例的答案格式不一样,那么答错是很正常的吧,我不太懂
In contrast, the performance gain becomes much less when using examples with different answer types (to MultiArith), confirming prior work [Min et al., 2022] that suggests LLMs mostly leverage the few-shot examples to infer the repeated format rather than the task itself in-context. Nevertheless, for both cases the results are worse than Zero-shot-CoT, affirming the importance of task-specific sample engineering in Few-shot-CoT.
- 难道这种特定的格式的prompt是一定要在大模型中才能使用的吗,如果小一些的模型就不能通过类似prompt的方式来增加思考的过程(或者说思考的时间边变长的方式来增加思考的准确性的),对于多模态的工作也是同理
学习
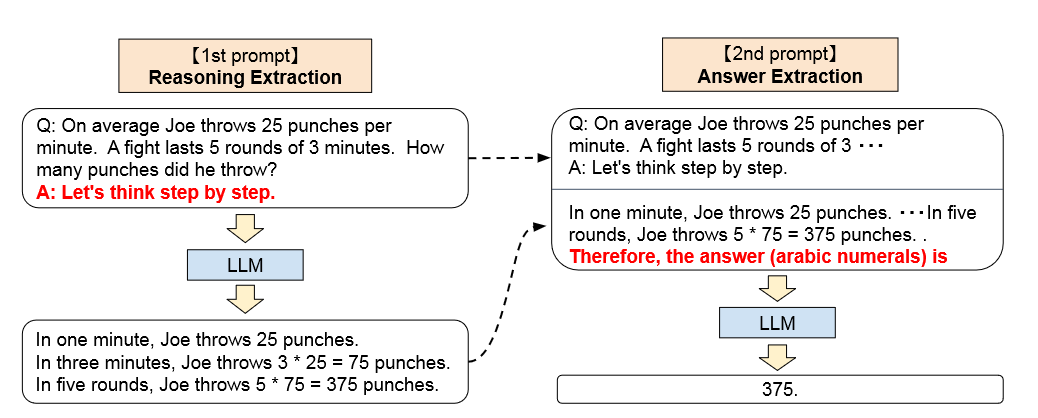
We compare our Zero-shot-CoT mainly to standard Zero-shot prompting to verify the effectiveness of its chain of thought reasoning.
Our simple method not only is the minimalist and strongest zero-shot baseline for difficult multi-step system-2 reasoning tasks that long evaded the scaling laws of LLMs, but also encourages the community to further discover similar multi-task prompts that elicit broad cognitive abilities instead of narrow task-specific skills.
We have proposed Zero-shot-CoT, a single zero-shot prompt that elicits chain of thought from large language models across a variety of reasoning tasks, in contrast to the few-shot (in-context) approach in previous work that requires hand-crafting few-shot examples per task.
Prompt Engineering的网络博客以下内容待补全
2024.02.10
好多论文都没听说过
- Basic Prompting
- Instruction Prompting
- Self-Consistency Sampling
- Chain-of-Thought (CoT)
- Automatic Prompt Design
- Augmented Language Models
Survey:Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing
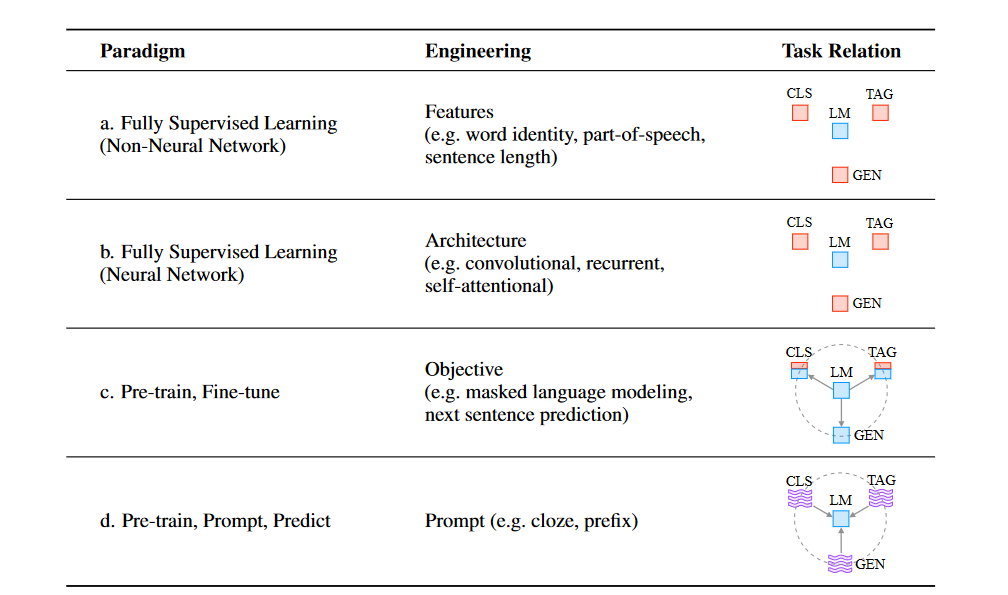
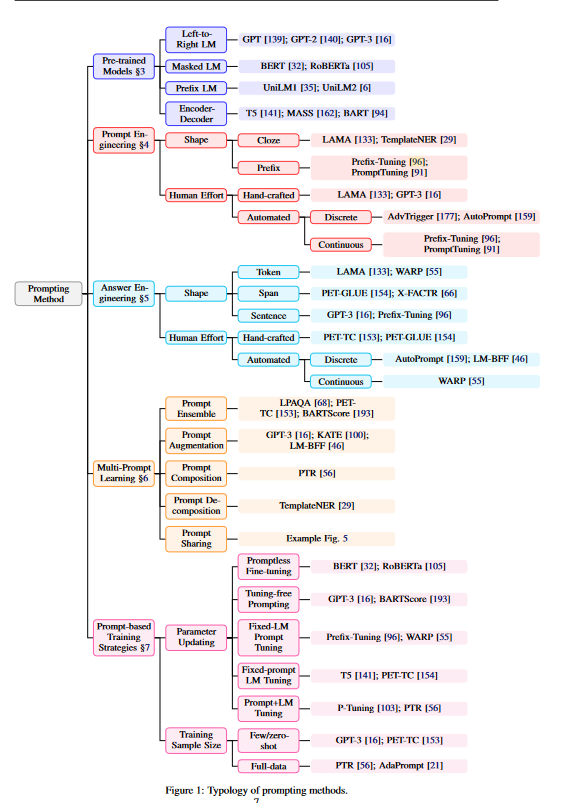
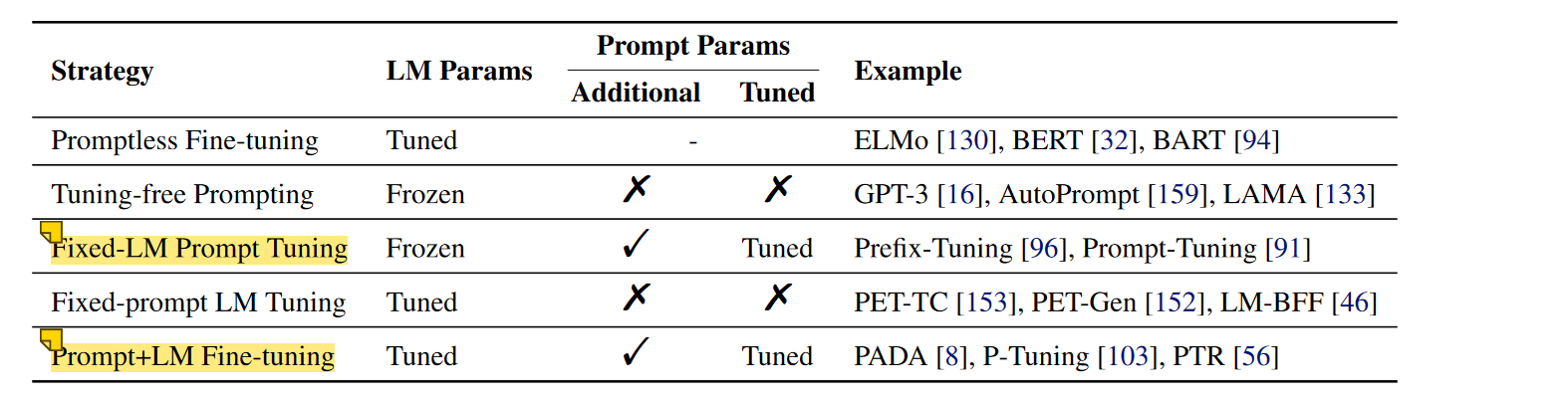
主要是介绍了NLP的发展脉络,从特征工程到目标工程,再到提示工程
我觉得最重要的图片是下面几张
Training data-efficient image transformers & distillation through attention(backbone)
泛读,https://www.bilibili.com/video/BV1L5411P7rV
backbone
背景
ViT训练数据太大,并且数据集不开源,训练困难
解决的问题
- 训练数据仅用ImageNet
- 8*V100比较小的资源
- 基于token进行蒸馏
方法
不同的损失函数
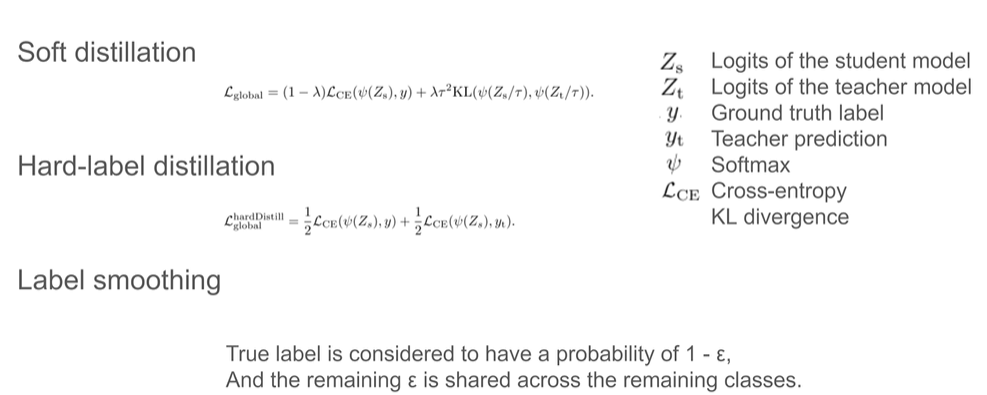
使用一个CLStoken和蒸馏token。训练的时候蒸馏token和teacher的结果进行计算损失,CLS和GT计算损失。预测的时候两边乘以0.5进行计算最终预测结果
![[论文简析]DeiT_ Data-efficient Image Transformers[2012.12877]_哔哩哔哩_bilibili_5'19.924''](http://qiniu-img.pion6.cn//%5B%E8%AE%BA%E6%96%87%E7%AE%80%E6%9E%90%5DDeiT_%20Data-efficient%20Image%20Transformers%5B2012.12877%5D_%E5%93%94%E5%93%A9%E5%93%94%E5%93%A9_bilibili_5'19.924''.jpg)
实验结果
自己看不贴了
AdaptFormer: Adapting Vision Transformers for Scalable Visual Recognition
附加结构型PEFT
NeurIPS, 2022
背景
这篇文章在VPT之后,他觉得VPT那种形式对于一些长输入token的tansformer模型效果不好,而且不具备普适性
- VPT那种形式对于一些长输入token的tansformer模型效果不好
- 不具备普适性
- VPT学到的内容不能很好的做迁移
方法
对transformer中的编码器结构的MLP,做了并行的结构,公式如下
而且这个$W_{down}$是把$x$从大变小,而$W_{up}$是从小变大中间有个$Relu$函数
下面还陈述了并行结构的很多好处
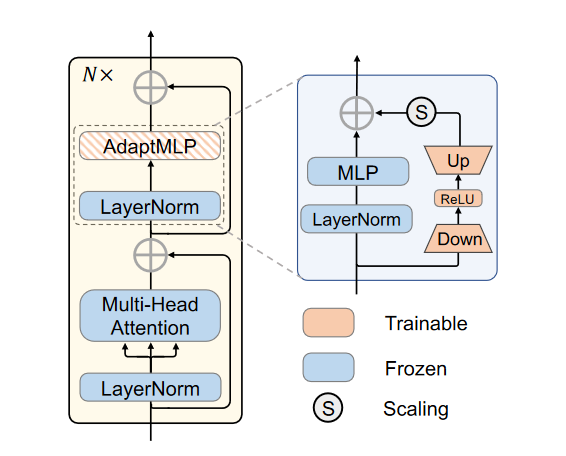
$$
\widetilde{x}l = ReLU(LN(x^`l) · W{down}) · W{up}.
$$$$
x = MLP(LN(x_l^)) + s · \widetilde{x}_l + x_l^
$$
结论
实验
- 和finetune作对比,而且作对比的时候肯定是不如finetune的
- 和VPT作对比
结果
(1)我们提出了一个简单而有效的框架,即AdaptFormer,用于使视觉转换器适应大量的下游视觉识别任务,并避免彼此之间的灾难性干扰。据我们所知,这是第一个探索视频动作识别中高效微调的工作。
(2)我们排除了许多设计选择,并展示了AdaptFormer在参数放大时的卓越健壮性。
(3)在不同下游任务上的广泛实验表明,AdaptFormer的性能明显优于现有的微调方法。通过展示AdaptFormer在多个视觉基准上的有效性,我们希望我们的工作可以启发研究团体重新思考计算机视觉中的微调机制,并朝着灵活而通用的视觉识别Transformer模型迈进。
思考
这篇文章主要是提供了一个向transformer中添加了一个适配器结构,结果中了nips
这篇文章主要说的是在视频资源中,这类长token序列中添加了这个适配器结构,注意token长度也是一个可创新的点,我划线了
文章中还谈到了并行结构的设计的原因,已划线,这下面这两篇可以读一读,如果有空的话
Going deeper with convolutions.
Attention is not all you need: Pure attention loses rank doubly exponentially with depth.
关于如何进行参数初始化感觉也可以学一学4.1
并且和VPT进行可调参数增加实验的对比方法可以学一学4.3
还有参数的迁移不会特别影响下游任务(喜欢对比?)4.6
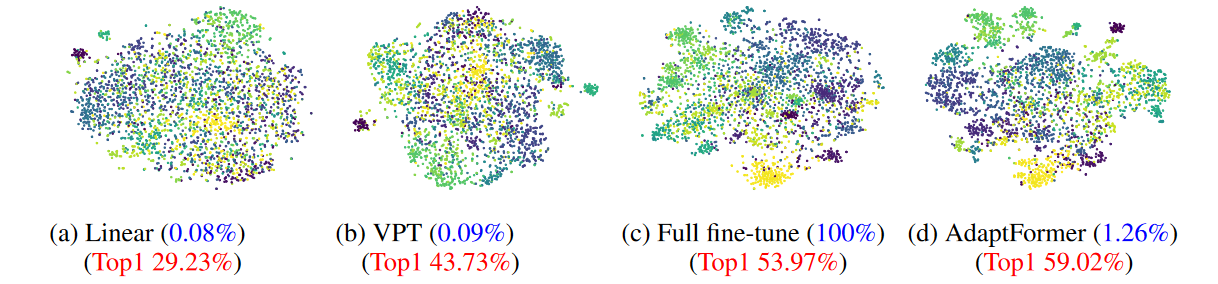
t-SNE 可视化4.7
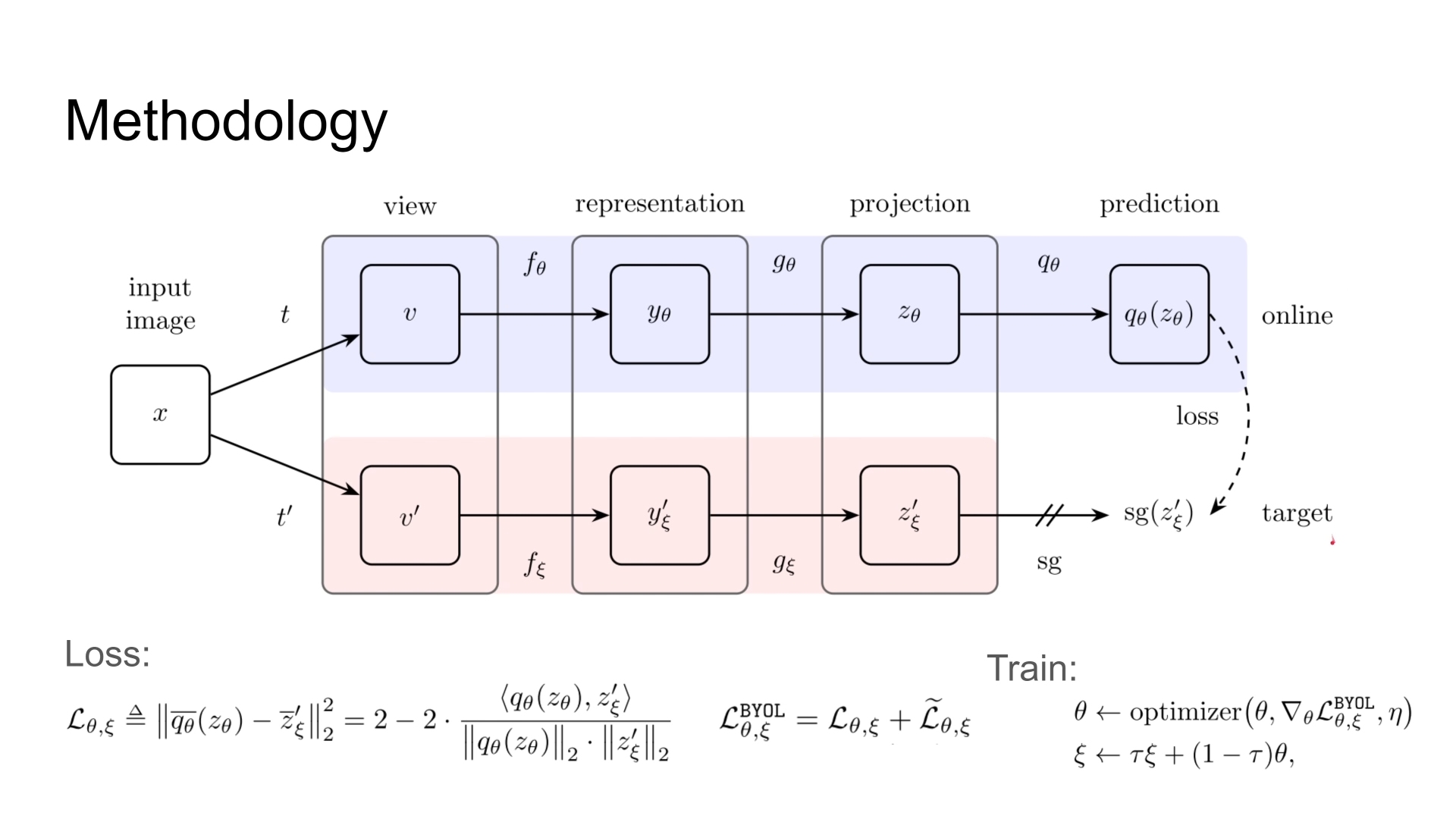
BYOL: Bootstrap Your Own Latent A New Approach to Self-Supervised Learning
泛读:https://www.bilibili.com/video/BV1ki4y1T7X4
是使用自监督的方式进行的pretrained-model,backbone
方法
流程如下:
- 对同一张图片进行不同的图像增强操作
- 输入到online模型和target模型中(这两个模型的除了最后一步中模型结构不同,其他的结构都完全相同,参数的话online模型的更新应该是先于target模型的)
- online模型中的结果经过了prediction之后,和target进行计算loss(我的理解是,因为t和t’有区别所以prediction用来弭平这个差距,最终使用这个loss更新online模型,target模型随后跟着online进行更新)
- 使这两个模型尽量靠近,但又不完全一样

结论
我觉得方法有点像左右互搏术

Exploring Simple Siamese Representation Learning
https://arxiv.org/abs/2011.10566
https://www.bilibili.com/video/BV1Ah411Q7Lb
孪生网络的类似EM算法假设
假设
这篇最重要的贡献就是提出了一种使用EM算法去解释孪生网络的假设
我们假设有以下的损失函数,总的来说是一个类似余弦相似度的,$\mathcal{T}$为图像增强函数,$\theta$为模型参数,$\eta_x$为图像对应的表征,可以把它理解为其中停止梯度的模型给出的对于图像的表征。
$$
\mathcal{L}(\theta,\eta)=\mathbb{E}_{x,\mathcal{T}}\Big[\left|\mathcal{F}_\theta(\mathcal{T}(x))-\eta_x\right|_2^2\Big].
$$
在上述进行假设之后,我们可以根据EM算法给出优化过程
对于优化$\theta$的过程,我们可以通过停止$\eta^{t-1}$的参数更新进行,也就是我上面提到的停止梯度的模型,因为EM算法一次只能更新一个参数。但是对于$\theta$更新的是那个左边的模型,也就是可以更新参数的那个模型
下面公式中的$\eta$其实就是相当于使用更新好模型参数的对于图片表征进行一次更新
$$
\theta^t\leftarrow\arg\min_\theta\mathcal{L}(\theta,\eta^{t-1})(7)\
\eta^t\leftarrow\arg\min_\eta~\mathcal{L}(\theta^t,\eta)(8)
$$
对于8式我们可以这样做近似,具体原因可以看论文
$$
\eta_x^t\leftarrow\mathcal{F}{\theta^t}(\mathcal{T}^{\prime}(x))(10).
$$
代入7式,可得以下式子
$$
\theta^{t+1}\leftarrow\arg\min_\theta\mathbb{E}{x,\mathcal{T}}\Big[\left|\mathcal{F}\theta(\mathcal{T}(x))-\mathcal{F}{\theta^t}(\mathcal{T}^{\prime}(x))\right|_2^2\Big]
$$
别忘记还有个Predictor,这个predictor其实是可以尽量去缩小之前我们在10式中的近似的影响的
这个假设是很重要的
SimCLR:A Simple Framework for Contrastive Learning of Visual Representations
http://arxiv.org/abs/2002.05709
https://zhuanlan.zhihu.com/p/378953015
其实和其他孪生网络相比感觉基本上没啥变化
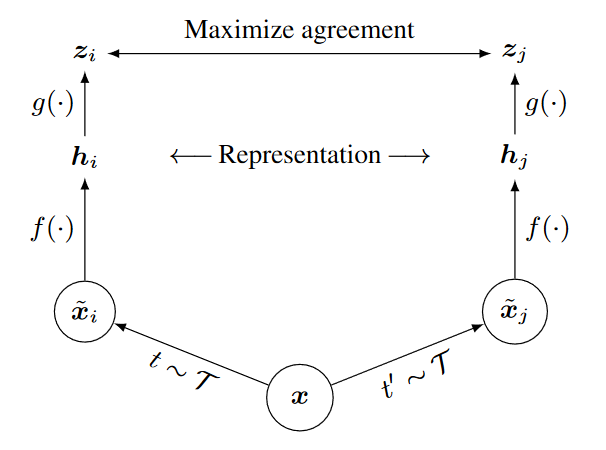
其实和其他孪生网络相比感觉基本上没啥变化,感觉主要是变了损失函数,以及引入了负样本。分子中的式子是同一张图片的不同变换所做的相似度内容。分母中的内容是同一批次中和其他内容做相似度的值的求和,最终按照这个式子求损失。
$$
\ell_{i,j}=-\log\frac{\exp(\sin(\boldsymbol{z}i,\boldsymbol{z}j)/\tau)}{\sum{k=1}^{2N}\mathbb{1}{[k\neq i]}\exp(\sin(\boldsymbol{z}_i,\boldsymbol{z}_k)/\tau)}
$$